
今年もアドベントの季節がやってまいりました。ということで R Advent Calendar 2013 の最初の記事です。
初っ端から小難しい話を出すのもアレなので, R において最も基本かつ重要なデータ構造であるデータフレーム (data.frame) についてお話しします。
データフレームについて話す前に統計モデルについて復習しましょう。
統計モデルとは,現象の定式化です。より具体的には,観察値 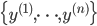 が得られたとき,
が得られたとき, 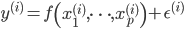 という形式で表すことです[A]。ここで
という形式で表すことです[A]。ここで 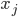 はモデルにおける入力値で,
はモデルにおける入力値で, 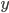 を説明するために必要であろうと解析者が考えている変数で,
を説明するために必要であろうと解析者が考えている変数で, 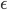 はランダム性のようにモデルで説明しきれない部分を押し込めたものです。
はランダム性のようにモデルで説明しきれない部分を押し込めたものです。
各 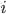 について, を与えると を得ることができます。したがって,個々の値を以下のように整頓して書くことができます。
について, を与えると を得ることができます。したがって,個々の値を以下のように整頓して書くことができます。
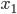 |
 |
|
|
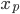 |
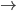 |
|
|---|---|---|---|---|---|---|
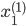 |
|
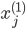 |
|
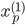 |
|
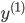 |
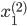 |
|
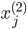 |
|
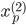 |
|
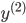 |
 |
|
|
|
|||
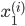 |
|
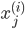 |
|
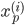 |
|
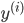 |
|
|
|
|
|||
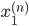 |
|
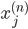 |
|
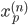 |
|
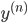 |
これが統計解析においてもっとも自然な形式で,そしてデータフレームと呼ばれるものです。統計モデルを作る際は,まずデータフレームを作成するのが基本となります。
さて,データフレームの各行は説明変数と応答変数のひとまとまりになっています。ということは,データフレームのデータは行ごとに保存されているのでしょうか。実はそうではありません。
統計モデルを作る場合,ある 1 つのモデルを作成したら終わりということはほとんどありません。複数のモデルを作成して良いモデルを選ぶということが必要になります。複数のモデルを作るために,説明変数を増やしたり減らしたりすることが必要になります。したがって,複数の統計モデルを組み立てるために説明変数の増減は容易であるべきです。そこで, R では,データフレームは,変数 (列) を単位としたデータ構造をとっています。
列を単位としたデータ構造をとっているということは,行方向の操作に対しては弱くなっています。よくよく考えてみると,行方向は具体的な値のまとまりなので,本質的には重要ではないのです。データフレームの本質は,変数 (列) にあるということは,意識しておくとよいのではないでしょうか。どのようにデータフレームを作ればよいかということに迷わなくなるでしょう。
R の話がほとんど出てこない R Advent Calendar 2013 の最初の記事でした。
脚注
- 単純な回帰モデルの場合。 [↩]