
Infer.NET には F# 向けのラッパーがあるので,ラッパーを用いない方法と比べてみます。お題は 2 枚のコインを投げて表と裏の出た結果からそのコインの偏りを推定するというものです。ただし,コイン 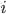
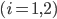 の表が出る確率は
の表が出る確率は 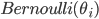 にしたがい,
にしたがい, 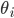 の事前分布を
の事前分布を 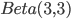 とします[A]。
とします[A]。
F# ラッパーを用いない書き方だと次のようになります。
open MicrosoftResearch.Infer open MicrosoftResearch.Infer.Distributions open MicrosoftResearch.Infer.Models let observedValues = [| [|true; true; true; true; true; false; false|] [|true; true; false; false; false; false; false|] |] let theta1 = Variable.Beta (3.0, 3.0) let theta2 = Variable.Beta (3.0, 3.0) for index = 0 to 6 do let y1 = Variable.Bernoulli (theta1) y1.ObservedValue <- observedValues.[0].[index] let y2 = Variable.Bernoulli (theta2) y2.ObservedValue <- observedValues.[1].[index] let engine = InferenceEngine (GibbsSampling ()) let posteriorTheta1 = engine.Infer (theta1) let posteriorTheta2 = engine.Infer (theta2)
F# ラッパーを用いる方法だと次のように書けます。
open MicrosoftResearch.Infer
open MicrosoftResearch.Infer.Fun.FSharp
open MicrosoftResearch.Infer.Fun.FSharp.Syntax
[<ReflectedDefinition>]
let coins () =
let observedValues = [|
[|true; true; true; true; true; false; false|]
[|true; true; false; false; false; false; false|]
|]
let theta1 = random (Beta (3.0, 3.0))
let theta2 = random (Beta (3.0, 3.0))
for index = 0 to 6 do
let y1 = random (Bernoulli (theta1))
let y2 = random (Bernoulli (theta2))
observe (y1 = observedValues.[0].[index] && y2 = observedValues.[1].[index])
theta1, theta2
Inference.setEngine (InferenceEngine (GibbsSampling ()))
let posteriorTheta1, posteriorTheta2 = Inference.inferFun2 <@ coins @> ()
コードクォートを使っているのと observe 関数で観察値を与えるので,コードがすっきりしています。ちなみに inferFunn 関数の第 2 引数に,第 1 引数の関数の引数を与えることもできます。
コードがすっきりするのは良いのですが,いろいろなはまりどころがあるので[B],簡単な場合でなければ F# ラッパーではなく,普通に C# 等で書く前者の書き方で書いた方が良いのではないかと思います。
ところで, Infer.NET はギブスサンプラーを使うときに事前分布が共役でないと実行できなくて不便です。数値的にサンプリングしてくれれば良いのですが,そのようなアルゴリズムの実装はデフォルトでは用意されていないみたいです。そんなわけで,頭を使わずに適当に解析したかったり,あるいは解析解が求められないような系では使いものにならないと思うのですが[C],これはどのように解決すれば良いのでしょうか。
脚注
- "Doing Bayesian Data Analysis" chapter 8 の例題より。 [↩]
- 例えば,事前分布に
random関数の引数を与えるのにパイプライン演算子 (<|) を使ったり, for ループでインデックスにArray.lengthを使ったりすると実行時に例外が発生してしまいます。他にもinferFunnの結果がIDistributionで,ランダムサンプルを取るというのができないのではないかと思います (前者の書き方の場合Inferメソッドの第 2 引数にQueryTypes.Samplesを与えればサンプルが結果になります)。 [↩] - 単に使い方を理解できていないだけのような気もしますが。 [↩]